よくある差分を取る話です。
データ量がそんなに多くないファイルの場合は、脳死でiterとかforとかでぐるぐる回せば出来ます。
しかし今回比較するCSVファイルが100万行以上あるデータだったので工夫しないと、後々痛い目に遭うと思い少し試行錯誤しました。
目次
環境
$ python -V
Python 3.10.2
$ pip show pandas
Name: pandas
Version: 1.4.2
Summary: Powerful data structures for data analysis, time series, and statistics
Home-page: https://pandas.pydata.org
Author: The Pandas Development Team
Author-email: pandas-dev@python.org
License: BSD-3-Clause
Location: /usr/local/lib/python3.10/site-packages
Requires: python-dateutil, numpy, pytz
Required-by:やりたかったこと
- 2つのCSVファイルを比較して差分をファイル出力する
- 差分ファイルの内容は以下をそれぞれ出力する
- 追加されたデータ
- 削除されたデータ
- 変更されたデータ
用意したCSVデータ
ダミーデータを生成する
以下のサイトで適当にデータを用意しました。データ件数はとりあえず1万件にしました。
こんな感じで、ダミーの氏名とメールアドレスを生成しました。
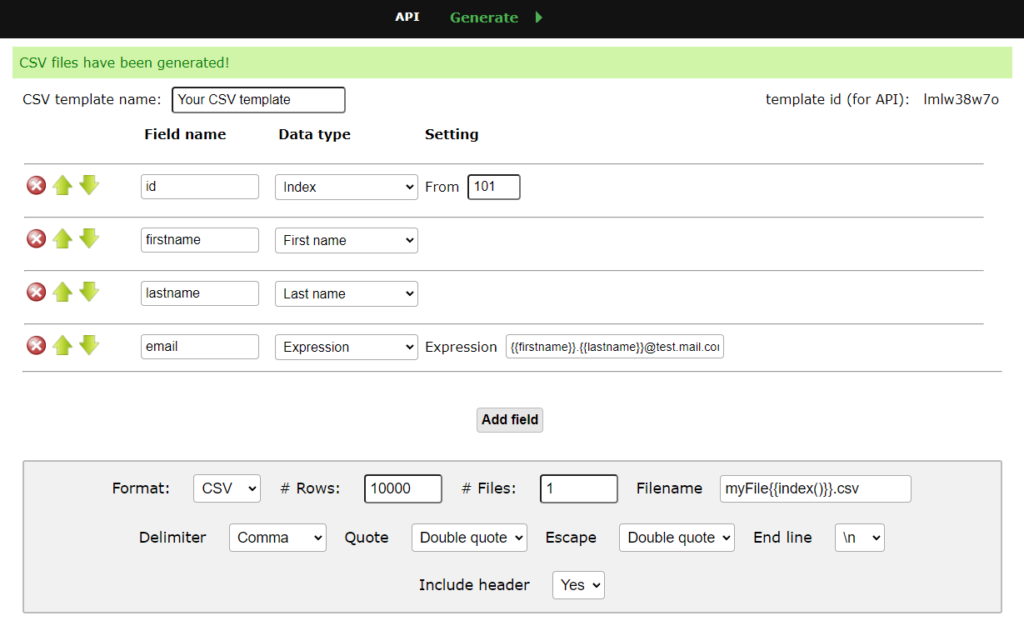
比較用に2つのCSVを作成する
生成したデータをcurrent_data.csvとして、コピーしてprevious_data.csvを作成しました。
差分を発生させるために、current_data.csvに対して適当にデータ追加、削除、変更を行っておきます。
id,firstname,lastname,email
101,Barbi,Screens,Barbi.Screens@test.mail.com
102,Ursulina,Bivins,Ursulina.Bivins@test.mail.com
103,Marylou,Janene,Marylou.Janene@test.mail.com
104,Fernande,Nikaniki,Fernande.Nikaniki@test.mail.com
105,Ulrike,Campball,Ulrike.Campball@test.mail.com
106,Darci,Tiffa,Darci.Tiffa@test.mail.com
107,Ninnetta,Tound,Ninnetta.Tound@test.mail.com
108,Gerianna,Isacco,Gerianna.Isacco@test.mail.com
109,Starla,Camden,Starla.Camden@test.mail.com
110,Jany,Bates,Jany.Bates@test.mail.com
~省略~id,firstname,lastname,email
100,Add,Test,Add.Test@test.mail.com
101,Barbi,Change,Barbi.Change@test.mail.com
102,Ursulina,Bivins,Ursulina.Bivins@test.mail.com
104,Fernande,Nikaniki,Fernande.Nikaniki@test.mail.com
105,Ulrike,Campball,Ulrike.Campball@test.mail.com
106,Darci,Tiffa,Darci.Tiffa@test.mail.com
107,Ninnetta,Tound,Ninnetta.Tound@test.mail.com
108,Gerianna,Isacco,Gerianna.Isacco@test.mail.com
109,Starla,Camden,Starla.Camden@test.mail.com
110,Jany,Bates,Jany.Bates@test.mail.com
~省略~とりあえずやってみる
脳死バージョンでやってみる
何分掛かるかをとりあえず計測してみたかったので脳死版を作成してみました。
DataFrameをぐるぐる回すのはいくつか方法はあるのですが、一番速いとどこかの記事で見かけたitertuples()を使いました。
かなり適当に書いているので改善点は他にもありそうな気がしていますがとりあえずの計測なので多めに見てもらえると助かります。
import time
import numpy as np
import pandas as pd
def diff_by_iter():
# dataframe from csv files.
previous_df:pd.DataFrame = pd.read_csv("./data/previous_data.csv")
current_df:pd.DataFrame = pd.read_csv("./data/current_data.csv")
# diff variables.
added_df:pd.DataFrame = pd.DataFrame()
deleted_df:pd.DataFrame = pd.DataFrame()
changed_df:pd.DataFrame = pd.DataFrame()
for previous_row in previous_df.itertuples():
match_df:pd.DataFrame = current_df[current_df["id"] == previous_row[1]]
if match_df.shape[0] == 0:
deleted_df = pd.concat([deleted_df, pd.DataFrame.from_records([previous_row], columns=previous_row._fields, index="Index")])
if match_df.shape[0] == 1:
previous:pd.DataFrame = pd.DataFrame.from_records([previous_row], columns=previous_row._fields, index="Index")
if not np.array_equal(match_df.values, previous.values):
changed_df = pd.concat([changed_df, previous])
for current_row in current_df.itertuples():
match_df:pd.DataFrame = previous_df[previous_df["id"] == current_row[1]]
if match_df.shape[0] == 0:
added_df = pd.concat([added_df, pd.DataFrame.from_records([current_row], columns=current_row._fields, index="Index")])
print("==================== added ====================")
print(added_df)
print("==================== deleted ====================")
print(deleted_df)
print("==================== changed ====================")
print(changed_df)
if __name__ == "__main__":
start = time.time()
diff_by_iter()
print ("processed time:{:.2f}".format(time.time() - start) + "[sec]")ぐるぐる回して追加、削除、変更されたデータを取得しています。
計測してみると以下の様な処理時間でした。
1万件でも結構な遅さですね。そもそも2回データを総なめしているのでまぁ遅いです。
単純計算だと100万件データがあった場合、100*6.99[sec]で10分程度掛かってしまう計算になります。遅い。
1. processed time:7.13[sec]
2. processed time:6.94[sec]
3. processed time:6.89[sec]
avg. 6.99[sec]ちょっと工夫したバージョンでやってみる
次にpandasのmergeを活用して差分を取得しました。
mergeした際のindicatorを有効にして、それで追加、削除データを取得するようにしています。
変更については単純に比較しているだけです。
先程の脳死版と比較するとコードもネストしてないのでスッキリしている気がします。
import time
import numpy as np
import pandas as pd
def diff_by_merge():
previous_df:pd.DataFrame = pd.read_csv("./data/previous_data.csv")
current_df:pd.DataFrame = pd.read_csv("./data/current_data.csv")
diff_df:pd.DataFrame = pd.merge(
previous_df,
current_df,
on=["id"],
how="outer",
indicator=True)
added_df:pd.DataFrame = diff_df[diff_df["_merge"] == "right_only"][["id", "firstname_y", "lastname_y", "email_y"]]
deleted_df:pd.DataFrame = diff_df[
diff_df["_merge"] == "left_only"][["id", "firstname_x", "lastname_x", "email_x"]]
changed_df:pd.DataFrame = diff_df[
((diff_df["firstname_x"] != diff_df["firstname_y"]) |
(diff_df["lastname_x"] != diff_df["lastname_y"]) |
(diff_df["email_x"] != diff_df["email_y"])) &
(diff_df["_merge"] == "both")][["id", "firstname_x", "lastname_x", "email_x"]]
print("==================== added ====================")
print(added_df)
print("==================== deleted ====================")
print(deleted_df)
print("==================== changed ====================")
print(changed_df)
if __name__ == "__main__":
start = time.time()
# diff_by_merge()
diff_by_merge()
print ("processed time:{:.2f}".format(time.time() - start) + "[sec]")圧倒的に早いですね。ぐるぐる回している分が完全に削れました。処理時間が約170分の1程度になりました。これであればデータ件数が多くなっても問題無い気がします。
1. processed time:0.04[sec]
2. processed time:0.04[sec]
3. processed time:0.03[sec]
avg. 0.04[sec]というかmergeって何だと思っている方はこちらから公式を参照ください。
簡単に言うとデータベースで言うところのテーブルのjoinですね。
それを活用して過去のファイルにしかないデータ(削除されたデータ)、現在のファイルにしかないデータ(追加されたデータ)をぐるぐる回さずに取得しています。
まとめ
- mergeを活用してファイル差分を取得することで処理時間を大幅に減らすことが出来た。(約170分の1程度)
- コードもネストが少なくなり多少見やすくなったと思う。
ただ、脳死版はまだ改善の余地はありそうなので実際の効果はもう少し落ちそうですが。